Limited Concurrency for Multiple API calls in React
21 Mar 2024Sometimes you have a list of several items that need to be processed by an API, like a list of documents to be summarized by a Large Language Model, or a selection of terms that trigger scraping jobs.
If these tasks are expensive (i.e.: they demand a lot from the server), or if there are rate limits, you may need to use a Limited Concurrency pattern to stop the server from being flooded with simultaneous requests.
This article explains how this was solved in React, using the awesome tanstack-query library.
The Problem
In developing Ollama Grid Search, a tool that allows users to test an AI prompt on a combinations of models and parameters, we had two requirements that relate specifically with the topic of this article:
-
Each test run could potentially generate dozens of expensive calls to the LLMs (and most likely those would be hosted locally), so we needed a way to stop the app from asynchronously sending all those calls to the API, potentially crashing the machine.
-
Users needed a way to re-run a single inference call (a combination of a model and several params), without having to perform an entire experiment again.
The Tanstack-query library makes implementing requirement #2 trivial (by using a function called refetchQueries()) and, with a little help, also makes the first one easily attainable too!
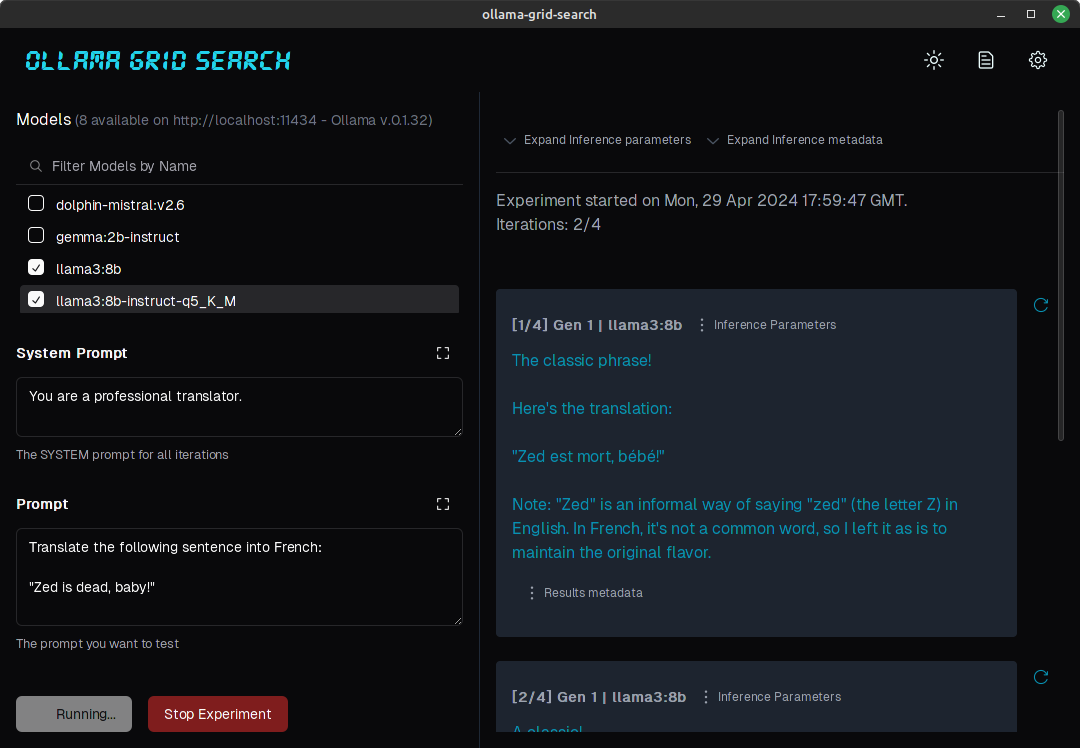
Inference calls are processed one at a time, but each combination of parameters can be re-queried individually.
The Solution
We were having a little trouble with an implementation of the Semaphore protocol, but luckily we came across this StackOverflow post.
const [selection, setSelection] = React.useState([])
const [noCompleted, setNoCompleted] = React.useState(0)
const results = useQueries(
selection.map((item, i) => ({
queryKey: ['something', item]
queryFn: () => fetchItem(item)
enabled: i <= noCompleted
staleTime: Infinity
cacheTime: Infinity
})
)
const firstLoading = results.findIndex((r) => r.isLoading)
React.useEffect(() => {
setNoCompleted(firstLoading)
}, [firstLoading])
The gist of it is:
1- Create an array of disabled queries.
2- Wait until one query is finished to start the next one.
While it didn’t work right out of the box for our use case, it eventually led us to the correct implementation! Keep reading!
(All credit to anton and spaceoso from StackOverflow!)
An Example Application
To better explain this concept we created a React Limited Concurrency Demo Application.
Let’s say we have a list of clients, and for each client we use a complex and expensive AI process to decide whether they are eligible for a discount or not:
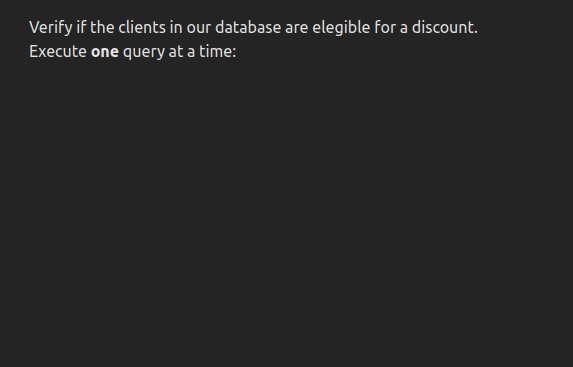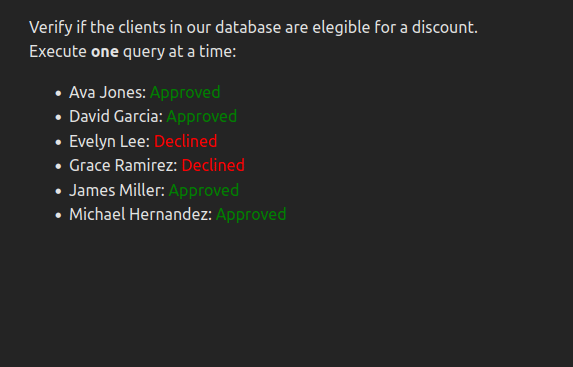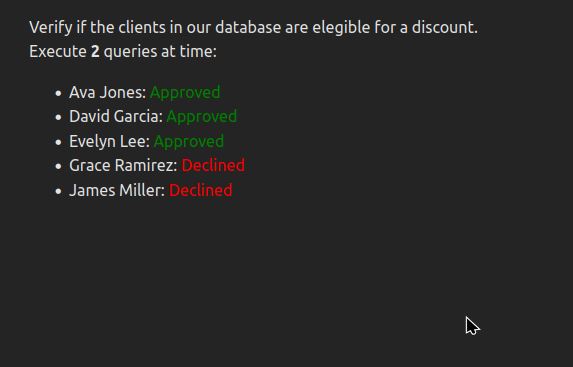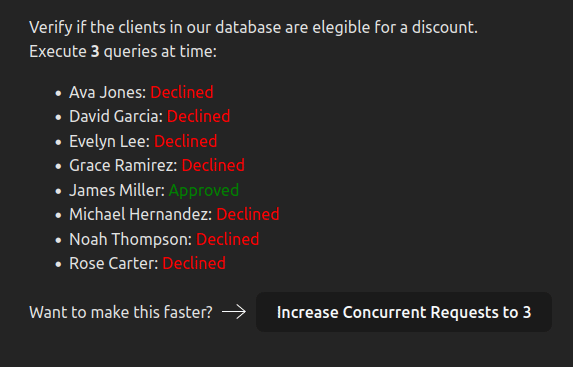
On the first run, each client is processed in sequence. This takes more time, but there is less load on the server
On the second run, processing time is faster, but the server has to handle concurrent calls.
The last run is clearly ideal from an user experience point of view, but it might make our servers crash, or ban us from a rate limited API (or even a regular website in the case of scraping)!
Limited concurrency allows you to control the number of simultaneous queries being sent and strike a balance between server load and processing speed.
Code
The relevant code can be seen in the List.tsx file in the application repository (some familiarity with tanstack-query is assumed).
Let’s break it down:
This is an API call simulation (it could be any regular fetch or axious call).
Let’s pretend it sends a client data to an AI server, that can take a few seconds to respond:
async function getInference(name: string) {
console.log("getting inference for", name);
const rand = Math.floor(Math.random() * 3) + 0.5;
await new Promise((res) => setTimeout(res, rand * 1000));
return {
name,
inference: Math.random() > 0.5,
};
}
We also have a fictitious list of clients that need to be processed:
const names = [
"Ava Jones",
"David Garcia",
...
]
Then start the component and set up the relevant state variables:
noCompleted controls the number of processed queries.
concurrentRequests controls how many queries can be allowed to run simultaneously
function List() {
const [noCompleted, setNoCompleted] = useState(0);
const [concurrentRequests, setConcurrentRequests] = useState(0);
Below is the most relevant part of the code!
Here we create an array of queries (notice that each gets its own queryKey).
Initially, only the first one (i===0) is enabled, so the querying starts when the component is mounted.
As a query finishes, we allow more queries to run.
const queries = names.map((name: string, i: number) => ({
queryKey: ["get_inference", name],
queryFn: () => getInference(name),
enabled:
i === 0 ||
(i <= noCompleted + concurrentRequests && noCompleted !== names.length),
}));
// Tanstack-query's useQueries hook can be used to fetch a variable number of queries
const results = useQueries({ queries: queries });
// Controls which queries have been processed
const lastFetched = results.filter((r) => r.isFetched);
In (i <= noCompleted + concurrentRequests && noCompleted !== names.length), if concurrentRequests is set to 0, only a single new query is allowed to run at a time.
Setting the value of concurrentRequests to anything higher than 0 “enables” more queries to run at a single time, with higher values allowing for a higher number of concurrent queries.
Finally, we update the state with the number of processed queries, so new queries can be allowed to run:
useEffect(() => {
setNoCompleted(lastFetched.length);
}, [lastFetched]);
To display the results, we iterate over the results array, checking if data is available for each individual result:
{
results.map(
(result: any, index: number) =>
result.data && (
<li key={index}>
{result.data.name}:
{result.data.inference ? (
<span style=>Approved</span>
) : (
<span style=>Declined</span>
)}
</li>
)
);
}
We could have displayed the entire list of clients, and updated each individual result as it was fetched… the code above is simplified for clarity.
Since each result could be mapped to a queryKey, we could use tanstack-query’s refetchQueries() to re-run queries for individual clients. This is useful in the server returns an error or a timeout (notice the “refresh” icons in the Ollama Grid Search screenshot).
Conclusion
Limited concurrency is easy to implement, and can be used to avoid taking down inference servers or being banned from an API, without sacrificing much in user’s experience.