Comparing Multiple Large Language Models in one Pass
28 Mar 2024This article aims to demonstrate how Ollama Grid Search can streamline the process of comparing and selecting Large Language Models (LLMs) for various tasks and provide answers to common questions such as:
What is the best model for for story telling?
I want to use LLMs to generate RPG scripts, which model should I use?
Getting started
The automation process we propose requires a few moving parts:
- Ollama installed and running (either on localhost or on a server the user has access to).
- Ollama Grid Search needs to be installed in the users machine.
Both dependencies above are free and can be installed in all major platforms.
Finally:
- The models for comparison need to have been pulled into the Ollama server.
Running tests
UPDATE:
As of v0.0.3, Ollama Grid Search lets you generate multiple responses for each single combination of parameters!
In this example, I’m building a RAG Fusion agent, and I need to decide between three models, which is the best at generating alternative, complementary queries to a prompt such as:
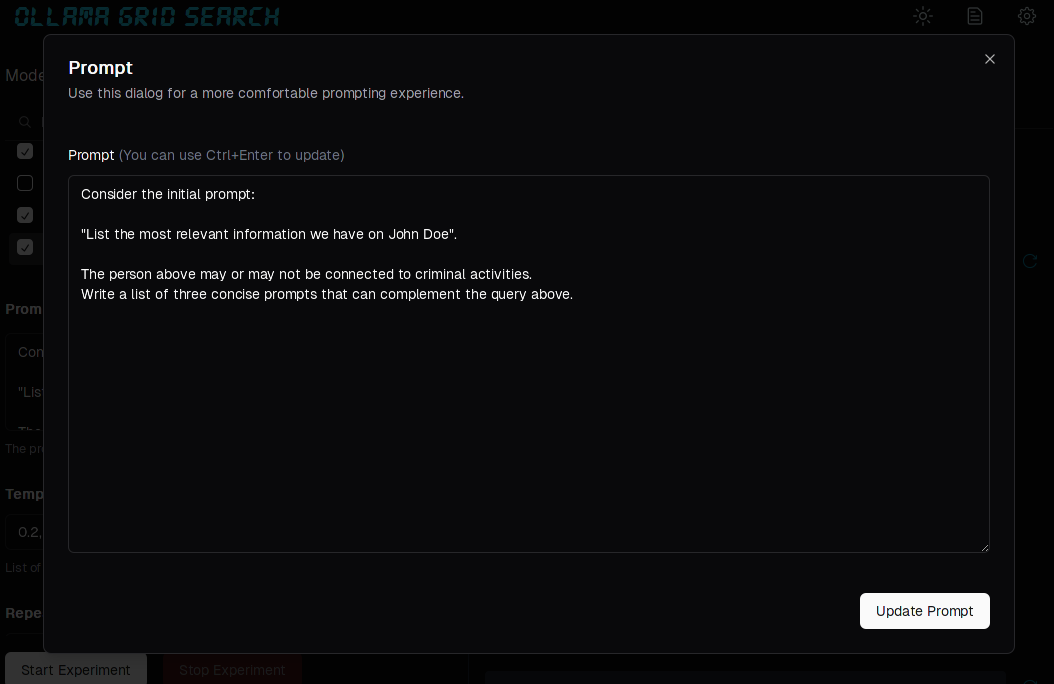
Consider the initial prompt:
"List the most relevant information we have on John Doe".
The person above may or may not be connected to criminal activities.
Write a list of three concise prompts that can complement the query above.
Ollama Grid Search is a Large Large Language Model testing desktop application. It lets us select the models we want to use, from a list of those installed on the server:
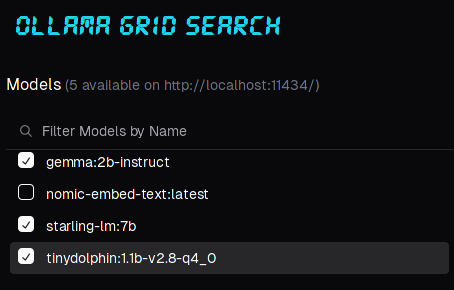
After selecting the three models above, we can enter the prompt:
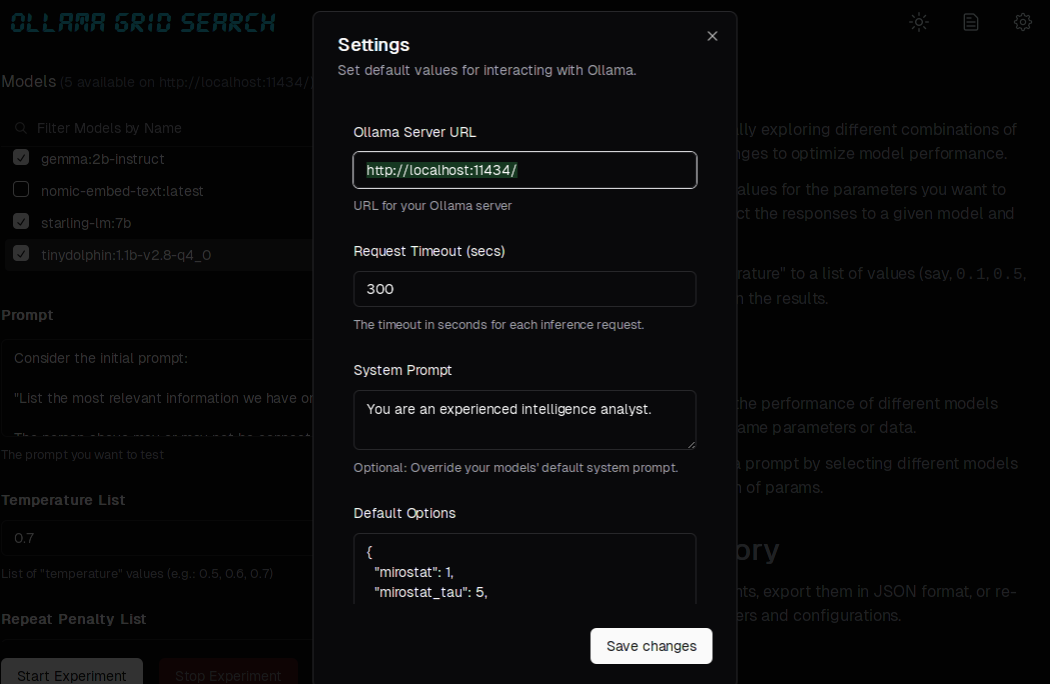
We can also click on the “gear icon” and use the “settings” options to set a custom system prompt:
Skip the temptation of messing with other parameters and hit “Start Experiment”.
The software will send the prompt (along with the system prompt and default inference paramenter) to each of the selected models sequentially and present an output similar to:
1/3 - gemma:2b-instruct
Sure, here are three complementary prompts that can be used to gather more relevant information about John Doe:
1. **What are John Doe's known affiliations and social media presence?**
2. **What are John Doe's past criminal records and legal cases?**
3. **What are John Doe's current whereabouts and living conditions?**
2/3 - starling-lm:7b
1. "Determine if John Doe has any known affiliations with criminal organizations."
2. "Investigate John Doe's financial and employment history for irregularities."
3. "Analyze John Doe's online presence and social media activity for potential threats or suspicious behavior."<|end_of_turn|>
3/3 - tinydolphin:1.1b-v2.8-q4_0
1. Who is John Doe, and what are his primary areas of interest?
2. What sources of information do you have on John's activities?
3. What conclusions can we draw from the available data regarding John's involvement in criminal activities?<|im_end|>
At first glance all results look pretty good!
But if we click on the "Expand Inference metadata" option (or in "Results Metadata", below each result), we can get a little more insight on how each model performed:
1/3 - gemma:2b-instruct
...
Created at: Thu, 28 Mar 2024 18:52:35 GMT
Eval Count: 74 tokens
Eval Duration: 0 hours, 0 minutes, 8 seconds
Total Duration: 0 hours, 0 minutes, 13 seconds
Throughput: 5.64 tokens/s
2/3 - starling-lm:7b
...
Created at: Thu, 28 Mar 2024 18:52:57 GMT
Eval Count: 65 tokens
Eval Duration: 0 hours, 0 minutes, 12 seconds
Total Duration: 0 hours, 0 minutes, 21 seconds
Throughput: 3.04 tokens/s
3/3 - tinydolphin:1.1b-v2.8-q4_0
...
Created at: Thu, 28 Mar 2024 18:53:01 GMT
Eval Count: 58 tokens
Eval Duration: 0 hours, 0 minutes, 2 seconds
Total Duration: 0 hours, 0 minutes, 4 seconds
Throughput: 13.29 tokens/s
For this particular experiment, tinydolphin’s throughput (the rate at which the model produces output) was 3 to 5x higher than the other models, while still delivering competitive results!
Running a lot more tests
But what if the results above were just a fluke?
Ollama Grid Search gives us the option of re-running iterations or experiments, but we can also set multiple combinations of parameters.
Let’s make the following changes:
- set Temperature List to
0.5, 0.7 - set Repeat Penalty List to
1.1, 1.5 - set Top_K List to
20,40
That’s 2 x 2 x 2 combinations of parameters for each of the 3 selected models, so we can expect 24 iterations for this new experiment.
Hit the “Start Experiment” button, optionally go get a cup of coffee, and wait for all iterations to run:
After inspecting the results we can see that throughput for all models stays consistent, but the quality and length of the output varies quite a lot, depending on the parameter combination selected for each iteration.
Starling-lm:7b, for example, returned some really verbose output:

For most combinations, however, Tinydolphin:1.1b-v2.8-q4_0 still returns good responses while remaining the fastest model!
We could now perform similar tests using a different prompt, or focus on that single model and perform a “grid search” experiment to determine its optimal combination of parameters (as discussed in Grid Search on Large Language Models using Ollama and Rust).
Conclusion
Manually testing multiple models can be a time drain and produce confusing results… there must be a method to the madness (this is a whisky reference, by the way)!
An automation tool like Ollama Grid Search helps us perform dozens of iterations in a single run, allowing us to see not only how models compare to each other, but also how they behave under a range of different parameters.
When we are pretty sure to have “winner” model, “grid search” experiments can be used to determine what set of parameters produces the best output for that model, and again save us from the hell of manual experiments.